SANA-WM:NVIDIA 用 26 亿参数造了一分钟的世界,然后开源了
2026 年 5 月,NVIDIA 研究团队开源了一个 26 亿参数的世界模型 SANA-WM。一张图片、一条相机轨迹,出 720p、一分钟长的视频。不是 demo 级别的"能看",是工业基线级别的"能用"。训练只用 213K 公开视频、64 张 H100 跑 15 天。推理?一张 GPU 搞定。
在所有人盯着 Sora 和 Kling 卷"视频好不好看"的时候,NVIDIA 在回答一个更底层的问题:一个能被控制的世界模型,需要多少资源?答案比你想的少得多。
先说结论:效率才是世界模型的真正战场
AI 视频生成走到 2026 年,"能出视频"已经不是新闻了。Sora、Seedance、Veo、Kling——每家都在拼画质、拼时长、拼"看不出来是 AI 生成的"。
但有个问题没人解决:你没法控制它。
你让 Sora 生成一段视频,只能说"镜头从左往右摇"。至于摇多快、摇到哪个角度、精确的相机路径——对不起,它不听你的。对于想用 AI 做游戏场景、做虚拟拍摄、做具身智能训练的人来说,这就不是"能不能看"的问题,是"能不能用"的问题。
SANA-WM 解决的就是这个问题。它是一个可控的世界模型——你给它一张起始图片和一条 6 自由度(6-DoF)的相机轨迹,它沿着这条轨迹生成一分钟的视频。相机路径精确到亚像素级别。
然后它开源了。
关键数据
| 维度 | SANA-WM |
|---|---|
| 参数量 | 2.6B(主模型),17B(第二阶段精炼器) |
| 输出 | 720p,60 秒视频 |
| 输入 | 1 张图片 + 6-DoF 相机轨迹 |
| 训练数据 | ~213K 公开视频片段 |
| 训练成本 | 64 张 H100,15 天 |
| 推理硬件 | 1 张 H100(标准版),1 张 RTX 5090(蒸馏版) |
| 蒸馏推理速度 | 60 秒 720p 视频,34 秒出片 |
| 吞吐量 | 比开源基线高 36 倍 |
| 开源状态 | 代码 + 论文已公开,模型权重即将发布 |
| 团队 | NVIDIA(Haoyi Zhu, Haozhe Liu, Song Han 等) |
四个设计选择,每个都在回答"为什么这么省"
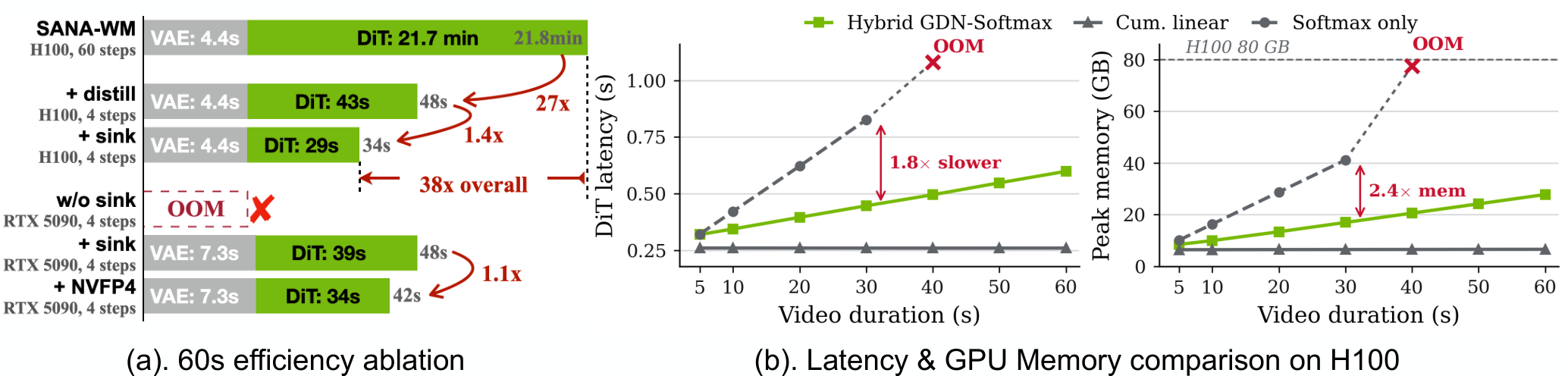
SANA-WM 的论文标题里有三个字:Efficient。这不是凑字数的。整个模型架构的每一步设计,都在对抗同一个敌人——长视频生成的显存爆炸。
1. Hybrid Linear Attention:用线性注意力打长上下文
标准 Transformer 的 softmax attention 计算复杂度是 O(n²)。60 秒 720p 视频,序列长度直接把显存打爆。SANA-WM 的解法是 Hybrid Linear Attention——帧内用 Gated DeltaNet(线性复杂度),周期性地插几层 softmax 保持全局一致性。
说白了就是:大多数时候用便宜的线性注意力,偶尔用贵的 softmax 做一次全局校准。 不是不用 softmax,是不用那么多次。
2. Dual-Branch Camera Control:两条路走同一条轨迹
相机控制是这个世界模型的核心卖点。SANA-WM 用了双分支设计:一个粗粒度的全局位姿分支做整体路径规划,一个细粒度的像素对齐几何分支做精确跟随。
两条分支的信息融合后,模型能精准到什么程度?论文里给了一个直接的指标:在自建的一分钟世界模型 benchmark 上,SANA-WM 的相机跟随精度超过所有开源基线。
3. Two-Stage Pipeline:先出长视频,再打磨质量
不是一步到位的。第一阶段用主模型(2.6B)生成完整的一分钟长视频,第二阶段用一个 17B 的精炼器提升纹理清晰度、运动流畅度和后半段质量。
两阶段的设计有个好处:你可以只用第一阶段做快速预览,满意了再跑第二阶段。 这在实际使用中省了大量时间。
4. Robust Annotation Pipeline:从公开视频里"抠"出训练标签
训练世界模型需要精确的相机位姿标注。这些标注要么用合成数据(不真实),要么人工标注(太贵)。SANA-WM 用了一个自动化流程——从公开视频里提取公制尺度的 6-DoF 相机位姿,直接当训练标签。
结果是:只用 ~213K 段公开视频,训练出了可比肩工业级基线的模型。 数据效率高到什么程度?作为对比,Sora 的训练数据估计在数百万到数千万视频的量级。
跟工业级基线比,它真的能打吗?
论文里列了三个对手:LingBot-World、HY-WorldPlay,以及若干开源基线。
视觉质量方面,SANA-WM 达到了工业级基线的可比水平(comparable)。不是碾压,是同一档。
但效率方面,它是碾压的:36 倍吞吐量优势。
这就是开源项目的价值所在——不一定要做到绝对第一,但要做到"人人能用"。LingBot-World 背后是多少资源?HY-WorldPlay 用了多少卡?SANA-WM 用 64 张 H100 训练 15 天,推理跑在单张 GPU 上。把门槛从"大厂专属"拉到了"实验室可用"。
对独立开发者意味着什么
说到这,你可能觉得这玩意儿跟独立开发没什么关系——一个 26 亿参数的视频世界模型,我又不是 NVIDIA。
但你换个角度想:
1. 游戏和虚拟场景的门槛在塌。 以前做一款 3D 游戏场景,你得会建模、会材质、会灯光。现在呢?一张概念图 + 相机路径 = 一分钟的 3D 世界漫游视频。虽然现在还是"视频"而不是"可交互的 3D 场景",但这条路的终点很明确。
2. 具身智能的训练数据有了一个新的生成方式。 机器人需要海量的"在真实世界里走动"的视频来训练。以前靠采集,成本极高。SANA-WM 能用一张照片生成任意相机路径的漫游视频,这意味着训练数据可以大量合成。
3. 开源的意义不只是"免费用"。 SANA-WM 的代码、论文、训练流程全部公开。这意味着你可以学到 NVIDIA 团队是怎么做 Hybrid Linear Attention 的、怎么设计双分支相机控制的、怎么从公开视频提取位姿标注的。这些技术方案才是真正的宝藏——模型会过时,方法论不会。
诚实边界:它现在还不能做什么
说几个它做不到的事,免得你期望太高:
- 不能生成人物运动。 它生成的是"世界在动"——风吹、水流、光线变化——但不会有人物走动、奔跑这类复杂动作。它是一个环境世界模型,不是角色动画引擎。
- 模型权重还没完全放出。 论文和代码已经公开,但模型权重标注的是 "Models (soon)"。可能要等几周。
- 720p 不是 4K。 画质跟工业级可比,但分辨率天花板在那。不过对于一个 2.6B 的模型来说,720p 已经相当不错了。
- 相机控制 ≠ 语义控制。 你能控制镜头往哪走,但不能说"让那扇门打开"或"让天气变成雨天"。语义级控制是下一代世界模型要解决的问题。
效率数字背后的哲学
最后说一个我觉得特别有意思的点。
SANA-WM 的蒸馏版能在一张 RTX 5090 上用 34 秒生成一分钟 720p 视频。RTX 5090 是消费级显卡,不是什么数据中心专属的怪兽。
这意味着什么?NVIDIA 在把世界模型从云端往本地推。 不是因为它做不出更大的模型,而是因为它看到了一个更大的市场——游戏、AR/VR、机器人训练、实时渲染——这些场景都需要本地部署。
把一件事做小、做快、做得人人能用,往往比做得最大最强更有战略意义。SANA-WM 的 2.6B 不是因为做不到 26B,是因为 2.6B 足以在一张消费级显卡上跑起来。
这跟做产品的道理是一样的——不是参数越多越好,是能跑在用户的设备上才算数。
链接
- 项目主页:nvlabs.github.io/Sana/WM
- 论文:arxiv.org/abs/2605.15178
- GitHub:github.com/NVlabs/Sana
- Hacker News 讨论:news.ycombinator.com